QDB Predictor
The QDB Predictor view for the archive described in this manual can be found here. It is important to note that all models in QsarDB repository can be used for the prediction purposes. This can be done on different levels:
- from chemical structure, when descriptor calculation is provided by the repository
- by entering descriptor values calculated in-house (usually with commercial software)
- or changing descriptor values with slider tool.
Currently descriptor calculation is possible for models that use CDK (version 1.4.9), XlogP3 (3.2.2), PaDEL-Descriptor (2.18 and 2.21) or DRAGON (6.0). View a separate list of models where prediction directly from chemical structure is enabled.
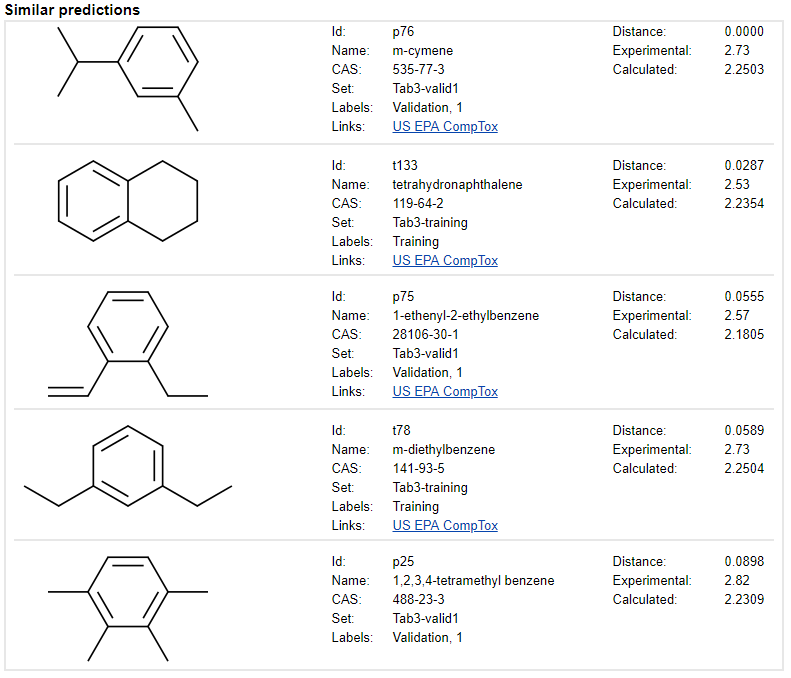
Model input
The QDB Predictor application enables the use of models for predictions and for understanding how independent variables (i.e., descriptors) contribute to the calculated property value. The QDB Predictor has various options for entering input data to perform the prediction. If the descriptor calculation is not enabled, then the descriptor values can be entered manually via the descriptor-input widget. It is also possible to browse compounds in the data set and to repeat predictions using the raw data contained in the archive.
Calculate descriptors
When the calculation of descriptors is implemented in the repository, the input structure for the prediction can be provided as a SMILES string or InChI code. In this case, the repository automatically calculates descriptors and evaluates the model.
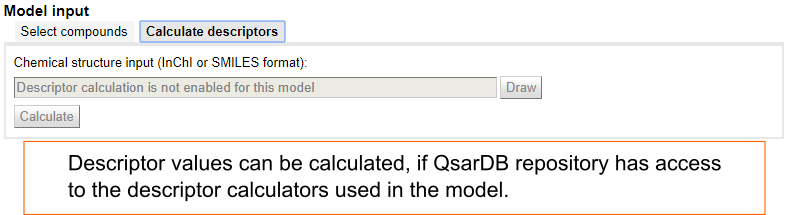
Model output
The output panel shows the equation for the prediction (available for MLR models) and the prediction result. It also provides an estimate whether the prediction for the compound is inside or outside of the model's applicability domain.

Prediction reports
Prediction reports can be downloaded in two different prediction reporting formats:
- EC Joint Research Centre's QSAR Prediction Reporting Format (QPRF)
- German Federal Environment Agency's (UBA) QSAR Prediction Reporting Format
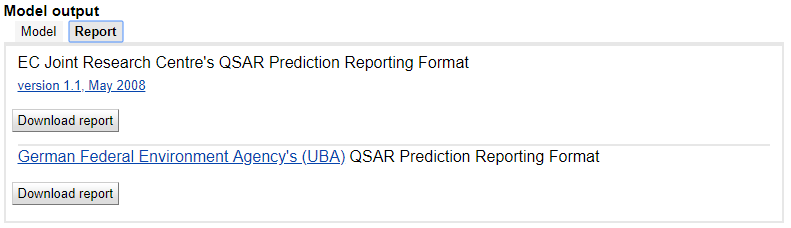
Similar predictions
Predictions are accompanied by the similarity analysis, where the relevant data about the most similar compounds from the dataset are presented for reference. The similarity criterion is the Euclidean distance calculated using the descriptor values of the compounds in the present setup. The visual comparison of the query compound with similar compounds and their experimental and calculated property values provide useful insights into the applicability domain of the model and the reliability of the prediction.