Validation
Validation tab is used to check the validity and consistency of inserted data. The user can choose between three validation levels: “basic”, “intermediate” or “advanced”. Validation can (1) pass cleanly, (2) pass with one or more warnings or (3) fail with at least one error. Warnings represent minor deficiencies (e.g., an optional Container attribute is missing) or general suggestions about how to improve the quality of the inserted data. Errors represent serious deficiencies (e.g., a required Container attribute is missing) or inconsistencies (e.g., broken Container relationships)
Basic validation
Basic validation (“sanity testing”) ensures that the QDB archive meets all structural and well-formedness requirements. The checks attempt to cover as many syntactic and semantic features as possible. Generic checks ensure that the Containers have their required attributes defined, that all declared Cargos are present in the archive, and that all system Cargos can be parsed without errors. In addition to generic checks, there are Container type-specific checks. For example, the validity of the CAS number and InChI code is checked for Compounds, the presence of mathematical representation is checked for Models, and so on. Another important type of check is the Container relationship check. For example, a Model container must refer to an existing Property via a strong relationship. Similarly, Property, Descriptor and Prediction containers must have “values” Cargo, and each value in the Cargo must refer to an existing Compound via a weak relationship.

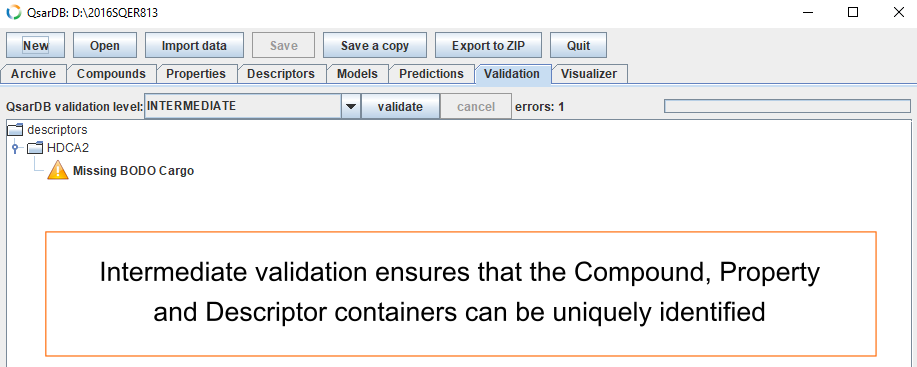
Intermediate validation
Intermediate validation (“reusability testing”) ensures that the Compound, Property and Descriptor containers can be uniquely identified. This validation level requires that all Compounds must have the InChI attribute, that the Properties must have both endpoint attributes with their units given as UCUM Cargo, and that the Descriptors must have the application attribute.
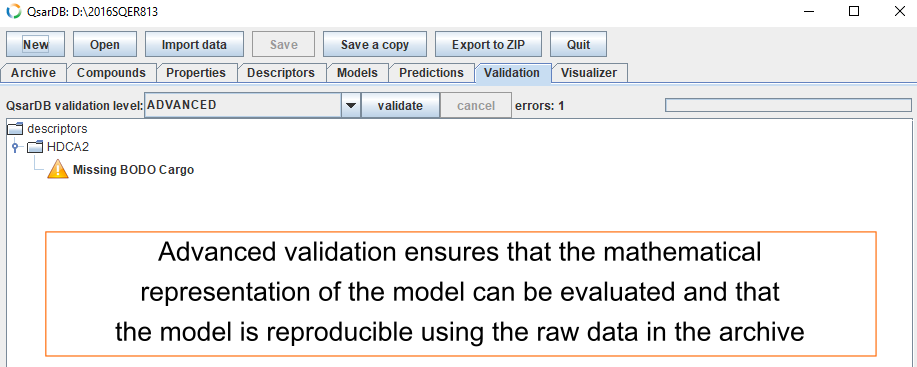
Advanced validation
Advanced validation (“reproducibility testing”) ensures that the mathematical representation of the model can be evaluated and that the model is reproducible using the raw data in the archive. At this validation level, each model is loaded, and its Predictions are re-evaluated with the included Descriptor data. The calculated Prediction values are compared with the Prediction values included in the archive.
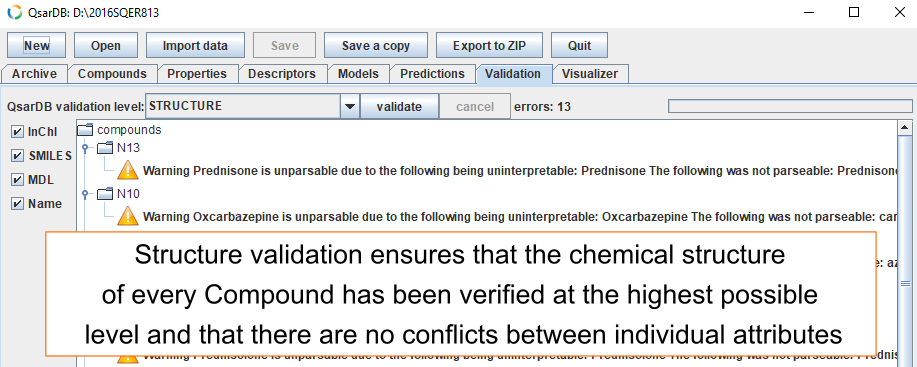
Structure validation
Structural validation ensures that the identity (i.e. the chemical structure) of every Compound has been verified at the highest possible level and that there are no conflicts between individual attributes.