The QsarDB repository & FAIR principles
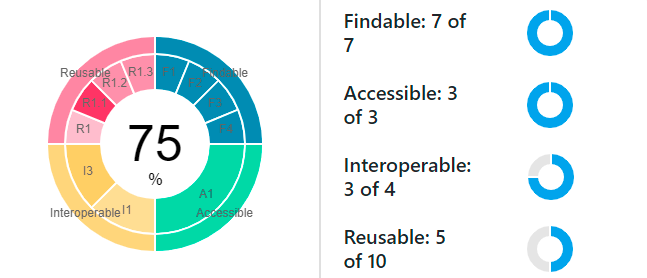
In today's world of scientific infrastructure, there is a lot of talk about the compliance of data with FAIR data principles. We decided to test the QsarDB data archives for compliance with FAIR data principles and we are pleased with the FAIRness of 75% for data and models in QsarDB.
FAIR data principles have been introduced in 2016 and have gained a strong momentum to improve the reusability of research data and enhancing its machine readability. The four elements of FAIR principles are Findability, Accessibility, Interoperability, and Reusability. These elements are related, but independently separable and data providers can adhere to these principles in combination and incrementally. Therefore, research data can be characterized with varying degrees of “FAIRness”.
European Union project FAIRsFAIR has proposed 17 core metrics to evaluate the FAIRness of research data. Currently 16 of these metrics can be automatically evaluated with the F-UJI web service. This web service calculates an overall FAIRness score and provides a detailed report about each individual measure.
We have used the F-UJI tool to evaluate and improve the fairness of the QsarDB repository. After some consultation and good advice from Andreas Jaunsen (from EOSC-Nordic & NordForsk) and Robert Huber (from FAIRsFAIR & PANGEA) we have reached a FAIRness level at about 75%. Although QsarDB archives receive maximum points for Findability and Accessibility, we still have work to do in terms of Interoperability and Reusability criteria.
Here is a typical result score summary for a QDB archive from the F-UJI web service: